
Recientemente, ha habido un aumento significativo en proyectos que incorporan funciones de IA generativa (LLM) en aplicaciones web. En particular, los sistemas RAG (Generación Aumentada por Recuperación) que buscan documentos internos para generar respuestas son una característica muy demandada por muchas empresas.
Si usas Next.js habitualmente como tu herramienta principal, es fácil pensar: '¿No sería suficiente con usar LangChain.js en API Routes (o Server Actions)?' Sin embargo, al intentar construir una aplicación de IA seria, rápidamente te enfrentas a una barrera arquitectónica.
Esta vez, explicaremos desde una perspectiva técnica 'por qué Next.js por sí solo es difícil' para la implementación de IA/RAG, y 'por qué se recomienda la configuración FastAPI + GCP Cloud Run'.
Límites de 'Next.js API Routes' al implementar funciones de IA
Next.js es un framework de pila completa muy bueno, pero tiene aspectos que no son adecuados para 'procesos pesados' o 'procesos de larga duración' como la IA generativa.
Problema de tiempo de espera de las funciones sin servidor de Vercel
Cuando se despliega Next.js en Vercel, el procesamiento del backend funciona como funciones sin servidor basadas en AWS Lambda. Aquí, el mayor enemigo es el límite de tiempo de espera.
- Hobby Plan: 10 segundos
- Pro Plan: 60 segundos (ampliable con configuración, pero con límite máximo)
Veamos el flujo de procesamiento de RAG.
- Vectorización (Embedding) de la pregunta del usuario
- Búsqueda de documentos relacionados en la Base de Datos Vectorial
- Envío de los resultados de búsqueda y el prompt combinados al LLM
- El LLM genera una respuesta (Generación de Tokens)
Si todo esto se realiza de forma síncrona, el tiempo de procesamiento puede superar fácilmente las decenas de segundos. Especialmente al usar modelos de alta precisión como GPT-4, la barrera de los 60 segundos es fatal. Mostrar un 'error de tiempo de espera' al usuario es inaceptable desde la perspectiva de la experiencia de usuario (UX).
Node.js vs Python: La diferencia en el ecosistema de IA
Aunque existen herramientas como LangChain.js para JavaScript (TypeScript), el estándar de facto para IA y aprendizaje automático es, sin duda, Python.
- Riqueza de bibliotecas: Las implementaciones y herramientas de investigación más recientes se publican primero en Python. Las versiones en JS suelen ir 'detrás' y sus funcionalidades pueden ser limitadas.
- Capacidad de procesamiento de datos: Python tiene una ventaja significativa en la integración con bibliotecas de procesamiento de datos como Pandas y NumPy.
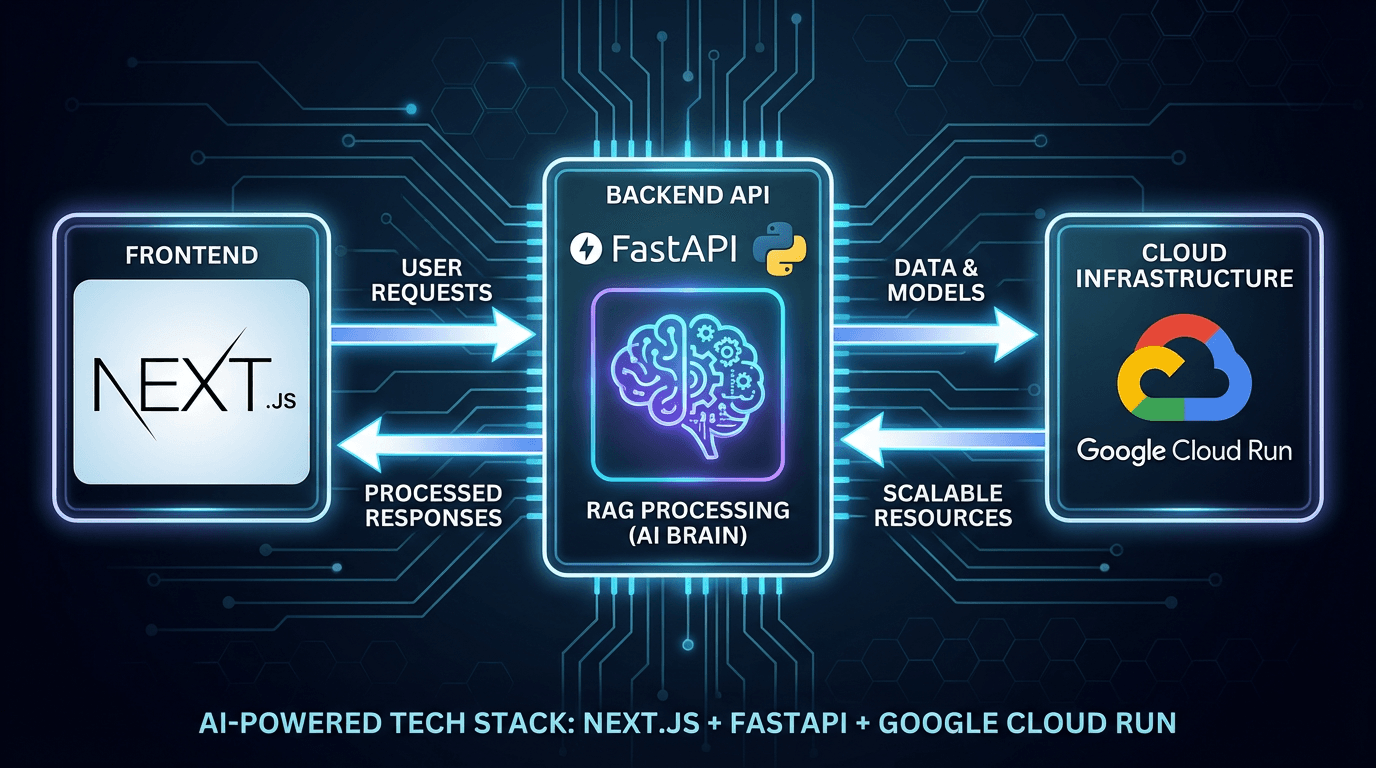
Solución: Arquitectura de separación del frontend y el backend de IA
La configuración recomendada para resolver los desafíos mencionados es la 'separación del frontend y el backend de IA'.
Diagrama de configuración: Next.js (BFF) + FastAPI (Backend) + Cloud Run
- Frontend (Next.js / Vercel): Renderizado de UI, autenticación, procesamiento de API ligero (rol de BFF).
- Backend (FastAPI / Cloud Run): Interacción con LLM, procesamiento RAG, cálculos pesados.
Esta configuración permite que Next.js se concentre en las responsabilidades de la UI, delegando los procesos pesados a un backend con límites de tiempo de espera más flexibles (o controlables).
¿Por qué elegir 'FastAPI' para el backend?
Aunque también existen frameworks web de Python como Django y Flask, FastAPI es abrumadoramente preferido en el desarrollo de IA.
Beneficios del procesamiento asíncrono (Async) y la seguridad de tipos (Pydantic)
El procesamiento de IA tiene inherentemente un largo 'tiempo de espera (I/O-bound)'. FastAPI soporta de forma nativa el procesamiento asíncrono (async/await), lo que permite manejar múltiples solicitudes concurrentes de manera eficiente.
Además, la definición de tipos y la validación mediante Pydantic son extremadamente potentes. Al permitir definir estrictamente las entradas y salidas del LLM (estructura JSON), se pueden prevenir errores al trabajar con Structured Output (salida de datos estructurada).
Capacidad de adaptación a bibliotecas modernas como LangChain / LlamaIndex
FastAPI tiene un diseño moderno y una alta afinidad con las principales bibliotecas de IA como LangChain. Por ejemplo, LangServe, que expone la interfaz Runnable de LangChain directamente como una API, también está construido sobre FastAPI.
¿Por qué elegir 'GCP Cloud Run' para la infraestructura?
Aunque AWS Fargate y Lambda también son opciones para alojar FastAPI, GCP Cloud Run destaca por su equilibrio entre experiencia de desarrollo y escalabilidad.
Cero diferencias de entorno con contenedores
Las aplicaciones de IA suelen tener dependencias de bibliotecas (paquetes de Python) complejas. Dado que Cloud Run permite desplegar contenedores Docker directamente, minimiza el problema de 'funcionó en local pero no en producción'.
Autoescalado basado en solicitudes y rentabilidad
Cloud Run puede configurarse para tener '0 instancias cuando no hay solicitudes (cero facturación)'. Además, el autoescalado es extremadamente rápido cuando aumentan las solicitudes. Además, se puede establecer un tiempo de espera máximo de solicitud de hasta 60 minutos, por lo que no hay que preocuparse por los tiempos de espera incluso en procesos de IA generativa que requieren mucho tiempo.
Puntos clave de implementación: Logro de la respuesta de streaming
Al usar esta configuración, es crucial implementar el streaming (visualización secuencial) para que el usuario no perciba tiempos de espera.
- En el lado de FastAPI, usar
StreamingResponsepara devolver los tokens generados de forma continua. - En el lado de Next.js, recibir ese stream y actualizar la UI en tiempo real.
De este modo, aunque el procesamiento general sea largo, el usuario no tendrá que seguir viendo una pantalla de 'Pensando...' constantemente.
Resumen: Aplicación de IA escalable con selección de tecnología adecuada
Next.js es un framework excelente, pero no es una 'bala de plata'.
- UI/UX: Next.js
- AI Logic: FastAPI (Python)
- Infrastructure: GCP Cloud Run
Combinando tecnologías de forma adecuada, se puede construir una aplicación de IA moderna que equilibre 'velocidad de desarrollo', 'estabilidad' y 'escalabilidad'.
Por favor, consideren esta arquitectura para su próximo proyecto de IA.
![Introducción práctica a la construcción de sistemas de chat con ChatGPT/LangChain [ Shingo Yoshida ]](/_next/image?url=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F8394%2F9784297138394_1_2.jpg&w=640&q=75&dpl=dpl_FYqBhuikYDMuNGE5MP5RYSgt6tk5)