
最近、Webアプリケーションに生成AI(LLM)機能を組み込む案件が急増しています。 特に、社内ドキュメントを検索して回答を生成するRAG(Retrieval-Augmented Generation)システムは、多くの企業で求められている機能です。
普段Next.jsをメインで使っていると、「API Routes(またはServer Actions)でLangChain.jsを使えば完結するのでは?」と考えがちです。しかし、本格的なAIアプリを構築しようとすると、すぐにアーキテクチャの壁に直面します。
今回は、AI/RAG実装において「なぜNext.js単体では厳しいのか」、そして「なぜFastAPI + GCP Cloud Run構成が推奨されるのか」を技術的な観点から解説します。
AI機能実装でぶつかる「Next.js API Routes」の限界
Next.jsはフルスタックフレームワークとして非常に優秀ですが、生成AIのような「重い処理」「長時間かかる処理」には適さない側面があります。
Vercel Serverless Functionsのタイムアウト問題
Next.jsをVercelにデプロイする場合、バックエンド処理はAWS LambdaベースのServerless Functionsとして動作します。ここで最大の敵となるのがタイムアウト制限です。
- Hobby Plan: 10秒
- Pro Plan: 60秒(設定で延長可能だが上限あり)
RAGの処理フローを見てみましょう。
- ユーザーの質問をEmbedding(ベクトル化)
- Vector DBから関連ドキュメントを検索
- 検索結果とプロンプトを組み合わせてLLMに送信
- LLMが回答を生成(Token生成)
これら全てを同期的に行うと、処理時間は容易に数十秒を超えます。特にGPT-4などの高精度モデルを使用した場合、60秒の壁は致命的です。ユーザーに「タイムアウトエラー」を表示させることは、UXとして許されません。
Node.js vs Python:AIエコシステムの差
JavaScript(TypeScript)向けにもLangChain.jsなどが提供されていますが、AI・機械学習のデファクトスタンダードは間違いなくPythonです。
- ライブラリの充実度: 最新の論文実装やツールは、まずPythonで公開されます。JS版は「後追い」になることが多く、機能が限定されている場合があります。
- データ処理能力: PandasやNumPyなどのデータ処理ライブラリとの連携において、Pythonには一日の長があります。
解法:フロントエンドとAIバックエンドの分離アーキテクチャ
上記の課題を解決するための推奨構成が、「フロントエンドとAIバックエンドの分離」です。
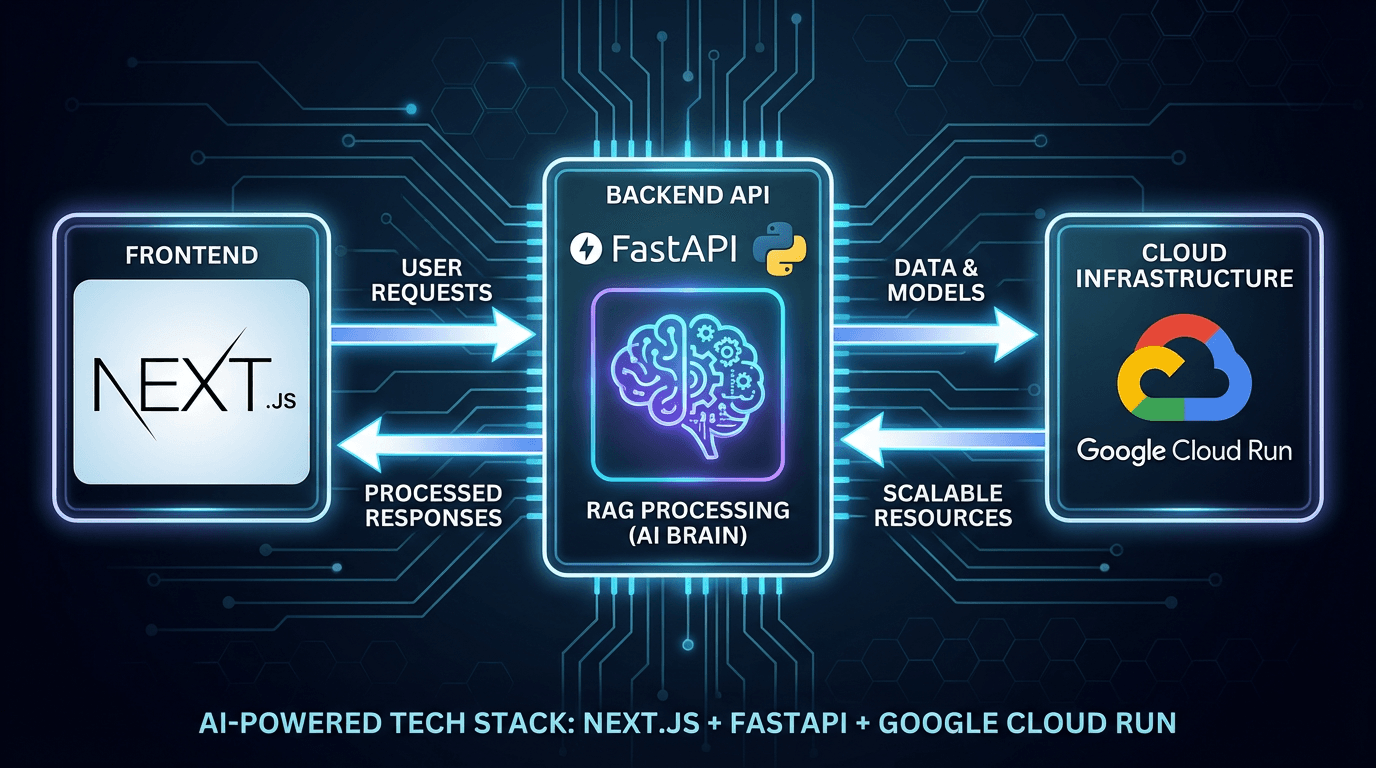
構成図:Next.js(BFF) + FastAPI(Backend) + Cloud Run
- Frontend (Next.js / Vercel): UI描画、認証、軽量なAPI処理(BFF的役割)。
- Backend (FastAPI / Cloud Run): LLMとの対話、RAG処理、重い計算処理。
この構成により、Next.jsはUIの責務に集中し、重い処理はタイムアウト制限の緩い(または制御可能な)バックエンドへ委譲できます。
なぜバックエンドに「FastAPI」を選ぶのか
PythonのWebフレームワークにはDjangoやFlaskもありますが、AI開発においてはFastAPIが圧倒的に支持されています。
非同期処理(Async)と型安全性(Pydantic)の恩恵
AI処理は基本的に「待ち時間(I/Oバウンド)」が長いです。FastAPIは標準で非同期処理(async/await)をサポートしており、同時リクエストを効率よく捌けます。
また、Pydanticによる型定義・バリデーションが非常に強力です。LLMの入出力(JSON構造)を厳密に定義できるため、Structured Output(構造化データ出力)を扱う際にバグを未然に防ぐことができます。
LangChain / LlamaIndexなど最新ライブラリへの追従性
FastAPIはモダンな設計であり、LangChainなどの主要なAIライブラリとの親和性が非常に高いです。例えば、LangChainのRunnableインターフェースをそのままAPIとして公開するLangServeもFastAPIベースで構築されています。
なぜインフラに「GCP Cloud Run」を選ぶのか
FastAPIをホストする場所として、AWS FargateやLambdaも選択肢に入りますが、開発体験とスケーラビリティのバランスでGCP Cloud Runが頭一つ抜けています。
コンテナベースで環境差異をゼロに
AIアプリは依存ライブラリ(Pythonパッケージ)が複雑になりがちです。Cloud RunはDockerコンテナをそのままデプロイできるため、「ローカルでは動いたのに本番で動かない」問題を最小化できます。
リクエストベースのオートスケールとコストパフォーマンス
Cloud Runは「リクエストが来ていない時はインスタンス数0(課金ゼロ)」に設定可能です。 また、リクエストが増えた際のオートスケールも爆速です。さらに、最大リクエストタイムアウトを最大60分まで設定できるため、生成AIのような時間がかかる処理でもタイムアウトの心配がありません。
実装のポイント:ストリーミングレスポンスの実現
この構成にする際、ユーザーに待ち時間を感じさせないためのストリーミング(逐次表示)の実装が重要です。
- FastAPI側で
StreamingResponseを使って、生成されたトークンを随時返却する。 - Next.js側でそのストリームを受け取り、UIをリアルタイム更新する。
これにより、処理全体が長くても、ユーザーは「考え中...」の画面をずっと見続ける必要がなくなります。
まとめ:適材適所の技術選定でスケーラブルなAIアプリを
Next.jsは素晴らしいフレームワークですが、「銀の弾丸」ではありません。
- UI/UX: Next.js
- AI Logic: FastAPI (Python)
- Infrastructure: GCP Cloud Run
このように適材適所で技術を組み合わせることで、「開発スピード」「安定性」「拡張性」を兼ね備えたモダンなAIアプリケーションを構築できます。
ぜひ、次回のAIプロジェクトではこのアーキテクチャを検討してみてください。
![ChatGPT/LangChainによるチャットシステム構築[実践]入門 [ 吉田 真吾 ]](/_next/image?url=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F8394%2F9784297138394_1_2.jpg&w=640&q=75&dpl=dpl_FYqBhuikYDMuNGE5MP5RYSgt6tk5)