
Recently, projects incorporating generative AI (LLM) functions into web applications have rapidly increased. In particular, RAG (Retrieval-Augmented Generation) systems that search internal documents and generate answers are features highly sought after by many companies.
When routinely using Next.js as the main framework, one might think, "Can't I just use LangChain.js with API Routes (or Server Actions) to complete this?" However, when attempting to build a full-fledged AI application, you quickly encounter the architectural wall.
This time, we will explain from a technical perspective "why Next.js alone is challenging" for AI/RAG implementation, and "why a FastAPI + GCP Cloud Run configuration is recommended."
Limitations of "Next.js API Routes" Encountered in AI Feature Implementation
Next.js is an excellent full-stack framework, but it has aspects that are not suitable for "heavy processing" or "long-running processes" like generative AI.
Vercel Serverless Functions Timeout Issue
When deploying Next.js to Vercel, backend processes run as AWS Lambda-based Serverless Functions. Here, the biggest enemy is the timeout limit.
- Hobby Plan: 10 seconds
- Pro Plan: 60 seconds (can be extended in settings, but with an upper limit)
Let's look at the RAG processing flow.
- Embed (vectorize) the user's question
- Search for relevant documents from the Vector DB
- Combine search results and prompt, then send to the LLM
- LLM generates a response (Token generation)
If all of these are performed synchronously, the processing time can easily exceed tens of seconds. Especially when using high-accuracy models like GPT-4, the 60-second limit is fatal. Displaying "timeout errors" to users is unacceptable from a UX perspective.
Node.js vs Python: Differences in the AI Ecosystem
Although LangChain.js and similar libraries are provided for JavaScript (TypeScript), the de facto standard for AI and machine learning is undoubtedly Python.
- Library Richness: The latest research implementations and tools are primarily released in Python first. JS versions often "follow behind" and may have limited functionality.
- Data Processing Capability: Python has an advantage in its integration with data processing libraries like Pandas and NumPy.
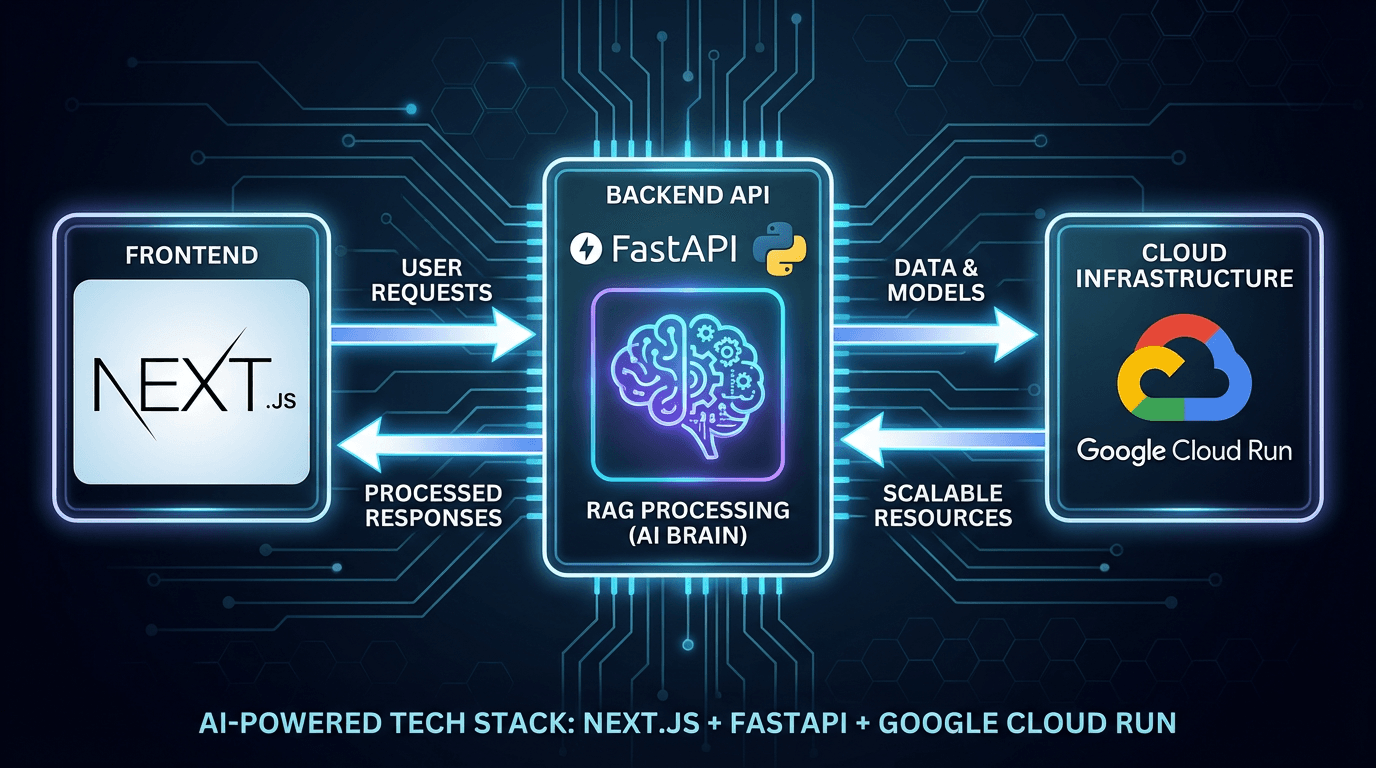
Solution: Separated Architecture for Frontend and AI Backend
The recommended configuration to solve the above challenges is a "separation of frontend and AI backend."
Architecture Diagram: Next.js (BFF) + FastAPI (Backend) + Cloud Run
- Frontend (Next.js / Vercel): UI rendering, authentication, lightweight API processing (BFF role).
- Backend (FastAPI / Cloud Run): LLM interaction, RAG processing, heavy computational processing.
This configuration allows Next.js to focus on UI responsibilities, while heavy processing can be delegated to a backend with more lenient (or controllable) timeout limits.
Why Choose "FastAPI" for the Backend?
While there are other Python web frameworks like Django and Flask, FastAPI is overwhelmingly favored in AI development.
Benefits of Asynchronous Processing (Async) and Type Safety (Pydantic)
AI processing typically involves long "wait times (I/O bound)". FastAPI natively supports asynchronous processing (async/await), efficiently handling concurrent requests.
Furthermore, type definition and validation with Pydantic are extremely powerful. It allows strict definition of LLM inputs/outputs (JSON structure), which helps prevent bugs when handling Structured Output.
Adherence to Latest Libraries like LangChain / LlamaIndex
FastAPI has a modern design and very high affinity with major AI libraries like LangChain. For example, LangServe, which exposes LangChain's Runnable interface directly as an API, is also built on FastAPI.
Why Choose "GCP Cloud Run" for Infrastructure?
While AWS Fargate and Lambda are options for hosting FastAPI, GCP Cloud Run stands out significantly in terms of developer experience and scalability balance.
Container-Based Approach Eliminates Environmental Differences
AI applications often have complex dependencies (Python packages). Cloud Run allows direct deployment of Docker containers, minimizing "works on my machine but not in production" issues.
Request-Based Auto-Scaling and Cost Performance
Cloud Run can be configured to have "0 instances (zero billing) when no requests are being made". Furthermore, auto-scaling when requests increase is extremely fast. Additionally, you can set the maximum request timeout up to 60 minutes, so there's no need to worry about timeouts even for time-consuming processes like generative AI.
Implementation Point: Achieving Streaming Responses
When implementing this configuration, streaming (sequential display) is important to prevent users from feeling long waiting times.
- On the FastAPI side, use
StreamingResponseto continuously return generated tokens. - On the Next.js side, receive that stream and update the UI in real-time.
This ensures that even if the overall processing is long, users do not have to continuously watch a "thinking..." screen.
Summary: Building Scalable AI Apps with Appropriate Technology Selection
Next.js is an excellent framework, but it is not a "silver bullet."
- UI/UX: Next.js
- AI Logic: FastAPI (Python)
- Infrastructure: GCP Cloud Run
By combining technologies appropriately, you can build modern AI applications that balance "development speed," "stability," and "scalability."
Please consider this architecture for your next AI project.
![ChatGPT/LangChain Chat System Construction [Practical] Introduction [ Shingo Yoshida ]](/_next/image?url=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F8394%2F9784297138394_1_2.jpg&w=640&q=75&dpl=dpl_FYqBhuikYDMuNGE5MP5RYSgt6tk5)